Spaced repetition recap
Mastering any subject is built on a foundation of knowledge: knowledge of facts, of heuristics, or of problem-solving tactics. If a subject is part of your full-time job, then you’ll likely master it through repeated exposure to this knowledge. But for something you’re working on part-time—like myself learning Japanese—it’s very difficult to get that level of practice.
The same goes for subjects in school: a few hours of class or homework a week is rarely enough to build up an enduring knowledge base, especially in fact-heavy subjects like history or medicine. Even parts of your life that you might not think of as learning-related can be seen through this lens: wouldn’t all those podcasts and Hacker News articles feel more worthwhile, if you retained the information you gathered from them indefinitely?
Spaced repetition systems are one of the most-developed answers to this problem. They’re software programs which essentially display flashcards, with the prompt on the front of the card asking you to recall the information on the back of the card. You can read more about them in Andy’s notes, or get a flavor from the images below drawn from my personal collection:



What gives these programs their name is how they space out repeatedly prompting you to review the same card, depending on how you self-grade your response. Increasing intervals after correct answers prevents daily reviews from piling up. This is how you can, for example, learn 10 new second-language words a day (3,650 per year!) with only 20 minutes of daily review time.
(If you’re still unconvinced and have some time to spare, I suggest Michael Nielsen’s post Augmenting Long-term Memory.)
Improving the scheduling algorithm
So far, this is all well-known. But what’s less widely known is that a quiet revolution has greatly improved spaced repetition systems over the last couple of years, making them significantly more efficient and less frustrating to use. The magic ingredient is a new scheduling algorithm known as FSRS, by Jarrett Ye.
To understand how these systems have improved, first let’s consider how they used to work. Roughly speaking, you’d get shown a card one day after creating it. If you got it right, you’d get shown it again after 6 days. If you get it right a second time, it’d be next scheduled for 15 days later. If you get the card right three times in a row, then it’s 37.5 days later. In general, after the 6-day interval, there’s an exponential backoff, defaulting to 6 × 2.5times correct + 1. You can see how, if you keep getting the card right, this can lead to a large knowledge base, with only a small number of reviews per day!
But what if you get it wrong? Then, you’d reset back to day 1! You’d see the card again the next day, then 6 days after that, and so on. (Although missing the card can also adjust its “ease factor”, i.e. the base in the exponential that is by default set to 2.5.) This can be a fairly frustrating experience, as you experience a card ping-ponging between long and short intervals.
If we step back, we realize that this scheduling system (called “SuperMemo-2”) is pretty arbitrary. Where does the rule of 1, 6, 2.5times correct + 1, reset back on failure come from? It turns out it was developed by a college student in 1987 based on his personal experiments. Can’t we do better?
Recall the theory behind spaced repetition: we’re trying to beat the “forgetting curve”, by testing ourselves on the material “just before we were about to forget it”. It seems pretty unlikely that the forgetting curve for every single piece of knowledge is the same: that no matter what I’m learning, I’ll be just about to forget it after 1 day, then 6 more days, then 15, etc. And sure, we can throw in some modifications to the ease factor, but it’s still pretty unlikely that the ideal review schedule is a perfect exponential, even if you let the base vary a bit in response to feedback.
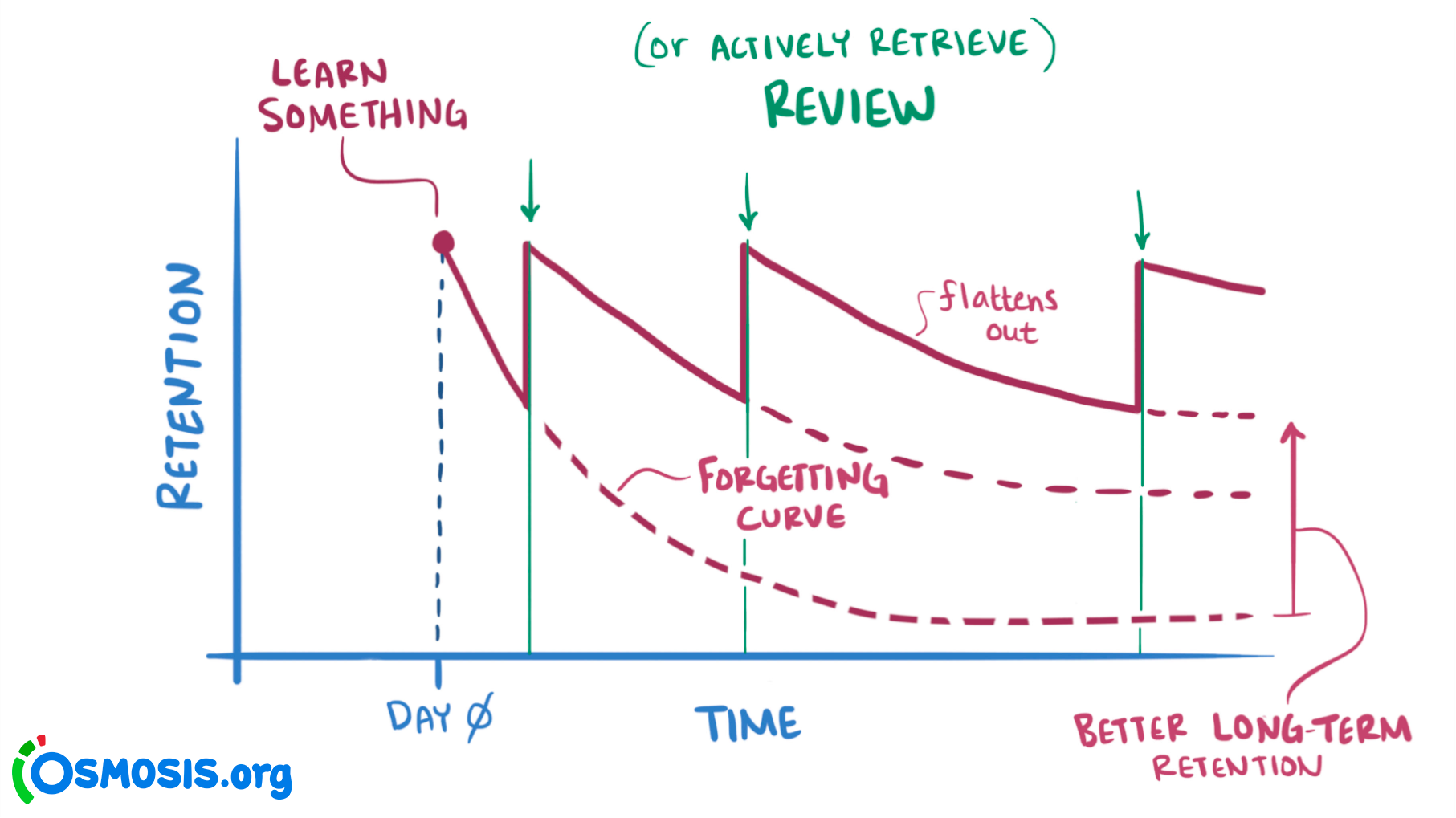 One of many illustrations of the forgetting curve. This one seems to have originated in a lecture on osmosis.org.
One of many illustrations of the forgetting curve. This one seems to have originated in a lecture on osmosis.org.
The insight of the FSRS algorithm is to concretize our goal (testing “just before we are about to forget”) as a prediction problem: when does the probability of recalling a card drop to 90%?. And this sort of prediction problem is something that machine learning systems excel at.
Some neat facts about how FSRS works
The above insight—let’s apply machine learning to find the right intervals, instead of using an arbitrary formula—is the core of FSRS. You don’t really need to know how it works to benefit from it. But here’s a brief explanation of some of the details, since I think they’re cool.
FSRS calls itself a “three-component” model because it uses machine learning to fit curves for three main functions:
- Difficulty, a per-card number between 1 and 10 roughly representing how difficult the card is
- Stability, which is how long a card takes to fall from 100% probability of recall to 90% probability of recall
- Retrievability, which is the probability of recall after a given number of days
For each card, it computes values for these based on various formulas. For example, the retrievability curve has been tweaked over time from an exponential to a power function, to better fit observed data.
The curve-fitting is done using 21 parameters. These parameters start with values derived to fit the curves from tens of thousands of reviews people have previously done. But the best results are found when you run the FSRS optimizer over your own set of reviews, which will adjust the parameters to fit your personal difficulty/stability/retrievability functions. (This parameter adjustment is where the machine learning comes in: the parameter values are found using techniques you may have heard of, like maximum likelihood estimation and stochastic gradient descent.)
Although the core FSRS algorithm concerns itself with predicting these three functions, as a user what you care about is card scheduling. For that, FSRS lets you pick a desired retention rate, with a default of 90%, and then uses those three functions to calculate the next time you’ll see a card, after you review it and grade yourself.
But if you want, you can change this desired retention rate. And because FSRS has detailed models of how you retain information, with its difficulty/stability/retrievability functions, it can simulate what your workload will be for any given rate. The maintainers suggest that you set the desired retention to minimize your workload-to-knowledge ratio.
This can have fairly dramatic effects: below we see two simulations for my personal Japanese vocab deck, with the orange line being the default 90% desired retention, and the blue line being the 70% desired retention which FSRS has suggested I use to minimize the workload-to-knowledge ratio. The simulation runs for 365 days, adding 10 new cards per day as long as I have less than 200 reviews. As you can see, the 70% desired retention settings have dramatically fewer reviews per day, in less time, while ending with many more cards memorized (because it doesn’t hit the 200 card limit that caps new cards).
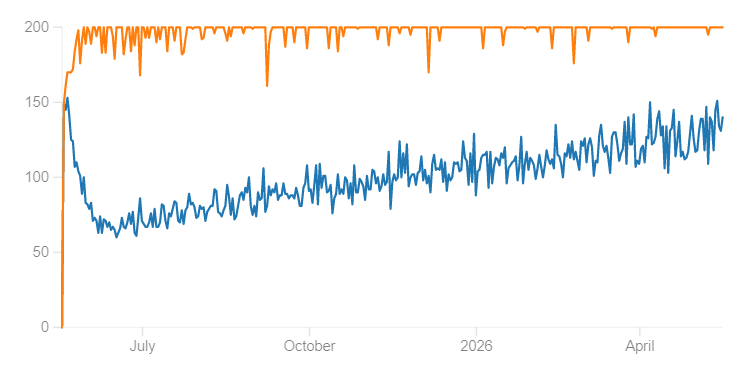 Reviews per day
Reviews per day
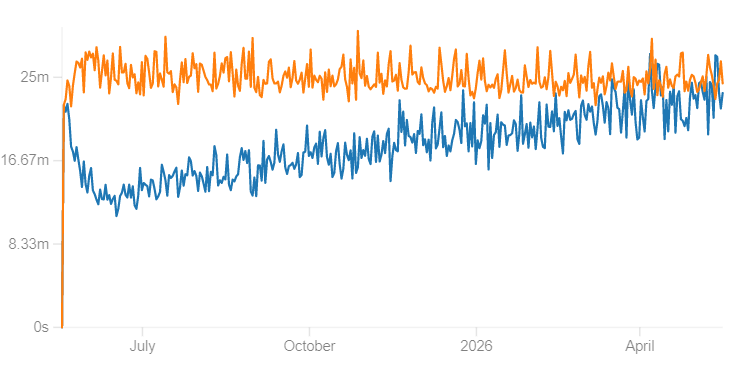 Time spent per day
Time spent per day
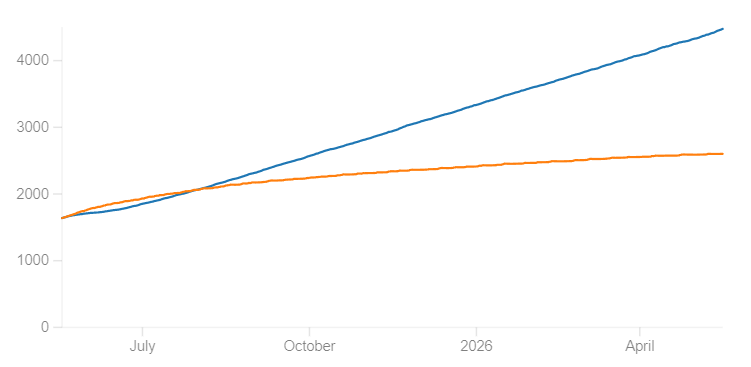 Number of cards memorized
Number of cards memorized
(Note that the 90% number used when calculating the stability function is not the same as desired retention. It’s just used to predict the shape of the forgetting curve. The original paper used half-life, i.e. how long until the card reaches 50% probability of recall, since that’s more academic.)
FSRS in practice
If you want to use FSRS, instead of other outperformed algorithms, you have to use software that supports it. The leading spaced repetition software, Anki, has incorporated FSRS since version 23.10, released in 2023-11. Unfortunately, it’s not the default yet, so you have to enable it and optimize its parameters for each deck you’ve created.
Correction: an earlier version of this article said FSRS was enabled by default, which is not true. I’d just had it enabled for so long that I’d forgotten!
By the way, the story of how FSRS got into Anki is pretty cool. The creator of FSRS, an undergrad at the time, posted on the Anki subreddit about his new algorithm. A commenter challenged him to go implement his algorithm in software, instead of just publishing a paper. He first implemented it as an Anki add-on, and its growing popularity eventually convinced the Anki developers to bring it into the core code!
Subjectively, I’ve found FSRS to be a huge upgrade to my quality of reviews over the previous, SuperMemo-2–derived Anki algorithm. The review load is much lighter. The feeling of despair when missing a card is significantly minimized, since doing so no longer resets you back to day 1. And the better statistical modeling FSRS provides gives me much more confidence that the cards Anki counts me as having learned, are actually sticking in my brain.
For Japanese language learning specifically, the advantages of FSRS are even stronger when you compare them to the “algorithms” used by two popular subscription services. WaniKani, a kanji/vocab-learning site, and Bunpro, a grammar-learning site, use extremely unfortunate algorithms, even worse than the 1, 6, 2.5times correct + 1 rule from SuperMemo-2. They instead have picked out other interval patterns, seemingly from thin air:
- For WaniKani: 4 hours, 8 hours, 1 day, 2 days, 7 days, 14 days, 1 month, 4 months, never seen again
- For Bunpro: 4 hours, 8 hours, 1 day, 2 days, 4 days, 8 days, 2 weeks, 1 month, 2 months, 4 months, 6 months, never seen again
These intervals don’t change per user or per card: they don’t even have an adjustable difficulty factor like the 2.5 base. And the idea that you’ll literally never see a card again after the last interval is terrifying, as it means you’re constantly losing knowledge.
But these aren’t even the worst part: the worst thing about these sites’ algorithms is that failing a card moves it down one or two steps in the interval ladder, instead of resetting to the first interval like SuperMemo-2, or predicting the best next interval using machine learning like FSRS. This greatly sabotages retention, wastes a lot of user time, and in general transforms these sites into a daily ritual of feeling bad about what you’ve forgotten, instead of feeling good about what you’ve retained. I wrote about this on the Bunpro forums when I decided to ragequit about a year ago, in favor of Anki.
Stepping back, my takeaway from this experience is that Anki is king. People complain about how its UI is created by developers instead of designers, or how you have to find or make your own decks instead of using prepackaged ones. These are all fair complaints. But Anki is maintained by people who actually care about learning efficiently. It receives frequent updates that make it better at that goal. And it’s flexible enough to carry you through any stage of your knowledge-acquisition journey. Putting in the time to master it will provide a foundation that lasts you a literal lifetime.
Learn more
If you’d like to learn more about this area, here are some of the links I recommend:
- Understanding the value of spaced repetition in general:
- More on the story of spaced repetition
- Details of how FSRS works:
- open-spaced-repetition/awesome-fsrs lists FSRS implementations in many programming languages, as well as flashcard and note-taking software that uses FSRS.
- open-spaced-repetition/srs-benchmark benchmarks FSRS against a bunch of other systems, including SuperMemo-2, previous versions of FSRS, the Duolingo algorithm, and more. (Interestingly, the only consistent winner against FSRS is a LSTM neural network, based on OpenAI’s Reptile algorithm. I’d love to learn more about that.)
Thanks to Expertium who reviewed an earlier draft of this essay for their comments and corrections.