In 2013, I started the project of designing a new streams API for JavaScript. The intent was to learn the lessons from Node.js’s streams, including its transition to “streams2”, and create something that could power various under-development web APIs. This site contains some essays from me reflecting on the API’s development, specifically as I worked to grapple with how different underlying resources (like files vs. sockets) could be abstracted behind a single primitive.
The result was the Streams Standard. These foundational classes now power a large variety of web APIs, from fetch() to translation. The Streams Standard APIs have been incorporated in various other JavaScript ecosystems as well, in a similar way to other web standards like URL, EventTarget, AbortController, fetch(), Worker, etc..
Recently, James Snell published an article “We deserve a better streams API for JavaScript” critiquing the Streams Standard APIs, and proposing an alternative he believes is more suitable for the JavaScript ecosystem. I appreciate James’s work on and insights into this problem space. I think the article has a number of solid points—James has identified real weaknesses, which I’ll get to—but his high-level framing has many questionable aspects, and a few that are just confused or wrong.
So let’s take this opportunity to dig into James’s arguments. I hope that while doing so, I can give some insight into how I thought about designing platform primitives, and some advice for those who will be pushing the platform forward in the future.
Optimizations
One of the most frustrating parts of James’s article is how he believes that his implementations’ performance problems are fundamental, and arise from the design decisions in the standard. This betrays a naïve mindset wherein implementers can get good performance out of the box, just by transcribing steps from specification text into JavaScript code.
If you step back for a minute and look at how standards work, you’ll quickly realize this is ridiculous. If a JavaScript engine implemented strings as a vector of 16-bit code units, and then whined about the “fundamental design decisions” that made it impossible to get good performance on string concatenation or === comparison, nobody would take them seriously. Standards are intended to be easy to follow, and to nail down observable consequences, so that various different implementations all give the same results. They are not an implementation roadmap, and making them performant is a large part of the job of a platform engineer.
The Streams Standard takes great pains to make as much unobservable as possible, so that optimized fast paths can be implemented. This is baked into the design at multiple levels. For example, the locking system means that stream1.pipeTo(stream2) can be optimized down to a sendfile(2) call. The higher-level APIs like async iteration mean that, in the common case, there’s no need to ever allocate promise objects or { value, done } containers. James has a whole section calling out “The hidden cost of promises”, which he opens by saying
Each read() call doesn’t just return a promise; internally, the implementation creates additional promises for queue management, pull() coordination, and backpressure signaling.
But “the implementation” is under his control! There is no need for it to create those promises, unless one of them is explicitly passed out to the developer’s JavaScript. James’s section “GC thrashing in server-side rendering” suffers from similar misunderstandings, assuming that every time the spec says to create an object, an actual garbage-collected object must be allocated.
In his section titled “The optimization treadmill”, James seems to recognize that well-written runtimes don’t need to have these problems. But he does so in a strange way, disparaging this foundational performance work as
every major runtime has resorted to non-standard internal optimizations
and complaining that
Finding these optimization opportunities can itself be a significant undertaking. It requires end-to-end understanding of the spec to identify which behaviors are observable and which can safely be elided.
I’m not really sure how to respond to this, except to say this is the job. When one implements a standard, whether it’s V8 implementing the JavaScript standard, ICU implementing the Unicode Standard, Chromium implementing the URL Standard, or Cloudflare Workers implementing the Streams Standard, one’s goal is to create a good, performant implementation. I guess, if you don’t like that part of the job, you can ask an AI agent to do it, as Vercel did. But complaining about it as “unsustainable complexity” is a surprising attitude for someone building a production runtime.
This pattern of blaming the standard for implementation quality issues continues in other places in James’s article, e.g. in his section “Exhausting resources with unconsumed bodies” where he complains about a Node.js bug, or in “Falling headlong off the tee() memory cliff” where he again complains that “implementations have had to develop their own strategies” instead of being handheld to the right approach.
In summary: it’s unreasonable to evaluate a standards-based API by looking at a naïve implementation. If you do that, then of course your from-scratch library which doesn’t have to meet any standards will be faster. It will certainly have fewer bugs, since you’ve written it after fixing various bugs in your original implementation of the standard API.
A similarly confusing section of James’s post is his section titled “The compliance burden” wherein he complains that … the API is too well-tested?
The rise of comprehensive test suites for standard APIs is one of the greatest triumphs of the 2010s. The web platform tests project, including efforts like the Interop 202X sprints, are probably the single greatest factor in moving us out of the 2000s hellscape. Interoperability is not perfect these days, but the edge cases we encounter now are nothing compared to back when Internet Explorer, Netscape/Firefox, and Safari all had divergent implementations of EventTarget, necessitating normalization layers like jQuery.
In the current era, the culture is clear. Everything that’s observable needs tests. Not just common cases, but error scenarios, invalidation, integration with other features: anything that might cause two implementations to diverge. If you discover a coverage gap, where implementations do different things, then add a test.
James complains
For runtime implementers, passing the WPT suite means handling intricate corner cases that most application code will never encounter. The tests encode not just the happy path but the full matrix of interactions between readers, writers, controllers, queues, strategies, and the promise machinery that connects them all.
It’s true that most application code will not encounter edge cases. But at internet scale, excluding “most” application code still leaves you with a lot of frustrated developers in the minority! One of the strengths of standards is their commitment to serve all developers’ scenarios interoperably, not just the common case. This is one of the major distinguishing factors between multi-implementation standards, and a library someone throws up on npm or lands on the main branch of nodejs/node.
What web streams (probably) got wrong
Although I find James’s high-level positions confused, at the more micro level I agree that he’s identified several weaknesses in the Streams Standard APIs. Many of these came from hewing overly-closely to the predecessor Node.js streams, and it makes sense that with 13 years of hindsight the community has been able to discover possible improvements.
Bring-your-own-buffer is unnecessary
I largely agree with James’s section “BYOB: complexity without payoff”. In retrospect, bring-your-own-buffer streams were designed with too much attention to theory and not enough to real-world performance and usability. Early discussions with Node.js core team members revealed their regret that Node.js streams always required buffer copies, and so Takeshi Yoshino and I galloped off to try to solve this problem.
In reality, memcpy() is not that slow. And it’s often necessary for security or architectural reasons anyway, as data needs to move across kernelspace/userspace boundaries, process boundaries, or just between the network stack and the JavaScript heap. The care we put into avoiding data races, via the transferral mechanism, was somewhat undercut by the release of SharedArrayBuffer in 2017. And the fact that we never came up with a design for zero-copy writable or transform streams is definitely a negative indicator.
Although it’s possible to imagine scenarios where reducing copies gives a useful speedup, my current thinking is that this doesn’t need to be baked into the generic stream primitive such that JavaScript stream creators, consumers, and library developers can all fully participate. Instead, it can be left as one of the many possible unobservable optimizations that implementations are allowed to do behind the scenes.
Backpressure and teeing are complicated
James’s section on “Backpressure: good in theory, broken in practice” is probing at a real problem. The Streams Standard’s notion of backpressure was coming from the unsophisticated approach used in Node.js’s streams1/streams2 designs. (It slightly modernized them and got rid of finicky details like how adding a "readable" listener would switch between backpressure modes.) It’s very believable to me that there are better models than the voluntary desiredSize + ready promise approach.
James’s new library includes four explicit backpressure modes. I don’t know whether all four of these modes are useful in real applications, or whether they’ve been battle-tested to the same extent the Node.js/Streams Standard design has. His choice of “strict” backpressure as the default seems unlikely to be correct: I doubt that many server-side developers want code that works fine over fast internet, when the user’s computer can quickly accept their server-rendered data, but throws exceptions when the user’s cell service goes down to one bar. But overall I agree that this is an area where giving developers more control is likely a good idea.
Similarly, he proposes two separate modes for handling backpressure when teeing, which the developer has to choose between. This is a good idea, which has been proposed for the Streams Standard.
Transform streams are another area where the Streams Standard may have been too influenced by its Node.js predecessor. James’s complaints in “Transform backpressure gaps” are chiefly about how transforms are eager, executing on write, instead of lazy, executing on read. We definitely are aware of this problem in the Streams Standard, although the causes are a bit different than what James describes.
The essential problem is that there’s no way for a WritableStream to signal that it wants no internal queuing, but is still willing to accept a single write. The canonical issue is whatwg/streams#1158, and there’s a draft pull request to close this expressiveness gap. As part of that, we’d make lazy transforms the default, with internal queuing in the transforms only when explicit highWaterMark options are passed.
But the complex way in which that solution works brings us to our next point…
Maybe, the whole thing could be much simpler
The biggest early decision we made with the Streams Standard was to have each half of the stream ecosystem be self-contained: ReadableStreams, backed by underlying sources, and WritableStreams, backed by underlying sinks. Again, this was inspired by the Node.js streams API, which used the same pattern (although smashed together into a single class).
The major alternative proposed was to merge the two halves, and have a single “channel” primitive: e.g.,
const { readable, writable } = new Channel();
where you could give out readable to consumer code, and write into writable to fill it. Or you could give out writable to producer code, and keep readable to see what they wrote.
To this day, I’m not sure which design is better. At the time, I convinced myself that the channel design wasn’t powerful enough for some of our goals. But looking back, I think I was too influenced by a desire to stay close to Node.js streams, and didn’t give the alternative a fair evaluation. James’s new library indeed takes the channel approach. And as his library shows, the channel design greatly simplifies transforms as well.
It’s possible that the channel design is too simple. There are certainly some patterns, largely around state management and queuing, which are much easier when the Streams Standard’s APIs manage them for you. With a channel-type API, individual stream creators need to implement those patterns themselves, and they might do so in slightly different ways. But my intuition is that those patterns have ended up being more rare than we expected in 2013. As such, I’m cautiously optimistic about exploration along this alternate evolutionary path.
Other thoughts on James’s library
A few rapid-fire thoughts on specific design choices in James’s library:
-
Error handling: the biggest gap in James’s post and library is any discussion of error handling. This is scary! Error handling in streams was one of the hardest things to get right, and one of the areas I’m most proud of our improvements in the Streams Standard vs. in Node.js. The distinction between no-fault cancelation of readable streams, error-like aborting of writable streams, errors that come from the underlying sinks and sources, and how all of these propagate when streams are wired together are quite complex, and crucial for ensuring program correctness. I don’t claim the Streams Standard’s design here is perfect—in particular, it was designed before AbortSignals and doesn’t integrate well with them—but I want to highlight this area for attention.
-
Bytes only: I’m skeptical that this will meet the ecosystem’s needs. It’s just too convenient to transform data into non-byte formats, such as text, or objects parsed from JSON. But if it does, it’s surely a huge simplification. The worry here would be bifurcating the ecosystem into byte streams, which are handled via James’s library, and object streams, which are handled by various other utilities.
-
Sync/async separation: I think this is a bad idea. Making consumers care about whether their data is coming from a sync source or an async source, with separate consumption methods for each, is a recipe for a bad time. Instead, the synchronous consumption hooks should exist, hidden inside the implementation, as part of the fast-path optimizations that James is so reluctant to implement. Consumers can pay the cost of a single promise at the end of the chain, and thus avoid unleashing Zalgo in the middle of their application code.
-
Streams are iterables: This is just the old objects-with-methods vs. freestanding functions debate. I think objects-with-methods have conclusively won the API design wars, at least in JavaScript, so I think James’s library is a developer-experience regression in this regard. Relatedly, James spends a lot of time complaining about the internal state machine of streams, but seems to ignore that async generators (which he uses to create his async iterables) have their own just-as-complex state machine.
-
No locking: James doesn’t like the Streams Standard’s locking APIs, and I agree they could be improved. But his design, of “just use async iterators”, kneecaps the many optimization opportunities that locked streams bring. How are you going to be able to convert your async iterable pipeline chain into sendfile(2) when at any time JavaScript code could call iterable.next()? Maybe this is one of those “intricate corner cases that most application code will never encounter”, and as long as nobody writes a test for it, we’ll be fine…
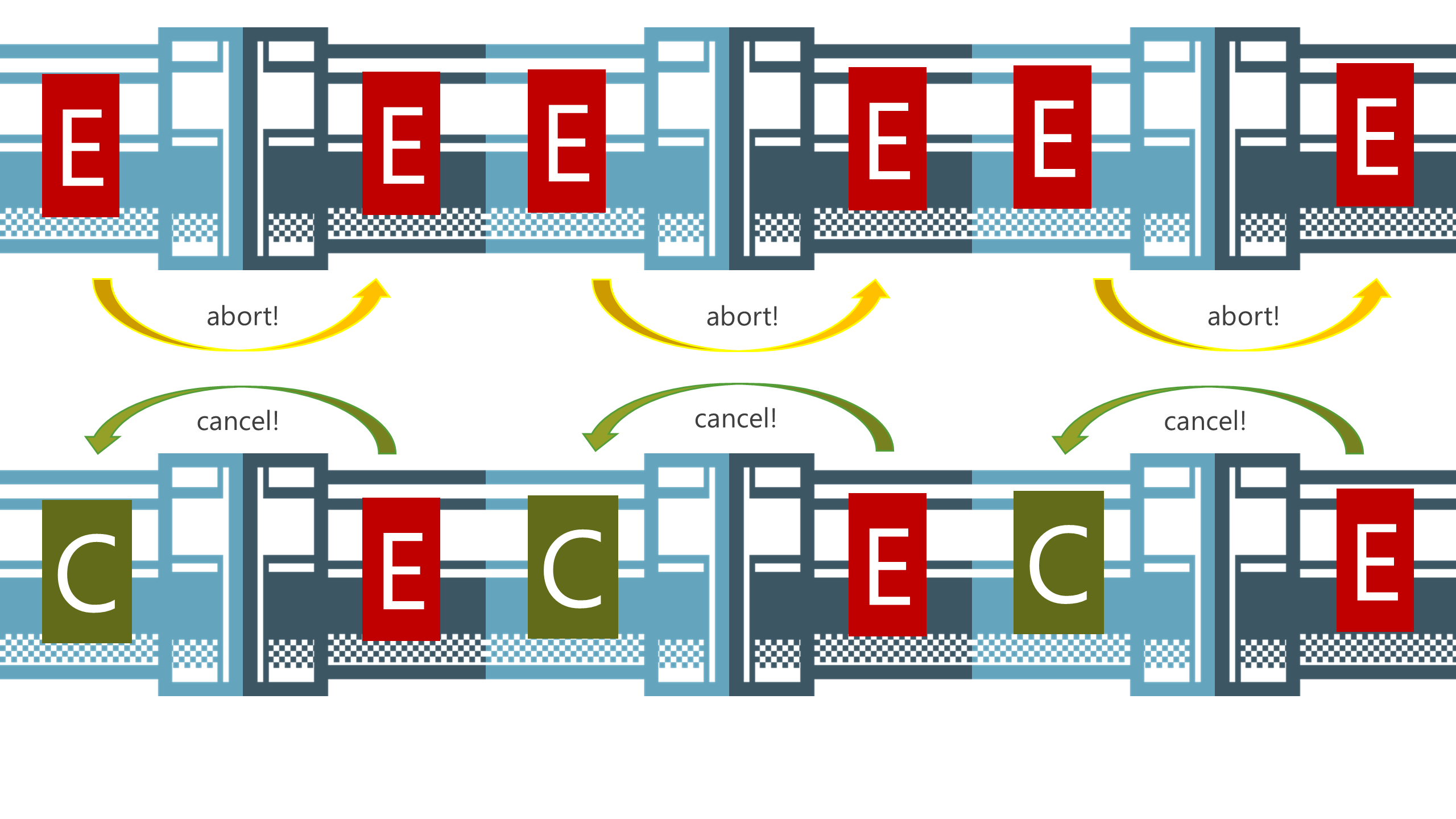 A slide from my 2014 presentation Streams for the Web, illustrating the abort and cancelation flow through pipe chains
A slide from my 2014 presentation Streams for the Web, illustrating the abort and cancelation flow through pipe chains
In conclusion
I’m grateful to James for starting this conversation, thus giving me a chance to reflect on the work myself and many others have put into the Streams Standard over the years. It’s certainly not perfect. But I think many of its core ideas are solid. And it’s important not to judge it based on buggy and naïve implementations, but instead as a standard that can be implemented either well or poorly.
For better or for worse, web APIs are forever: the web is not going to get a second streams API. So for any parts of the JavaScript ecosystem which want to use the same primitives as browser code, evolving and improving the Streams Standard is probably more fruitful than starting over from scratch. There have been many | previous | attempts to create secondary stream ecosystems that sit alongside the gorillas of Streams Standard streams or Node.js streams, and they’ve seen their own limited success. I wish James’s library the best success it can attain, within that tradition.
Unfortunately, evolving the Streams Standard is hard. In the ZIRP heydays of the 2010s, myself and collaborators could build primitives like promises, streams, modules, web components, and the like; getting the web platform’s foundations in order had a lot of business support. These days, it’s much harder to motivate directors at browser companies to spend their budgets on incremental improvements, when what we have is good enough. This is why even minor improvements are stalled for years. It’s possible for heroes to push through new features by single-handedly contributing specification text, web platform tests, and a browser implementation or two. But it’s definitely harder than writing a fresh JavaScript library.